LinkedList, Stack, Queue
1. LinkedList
LinkedList는 각 노드가 데이터와 포인터를 가지고 연결되어있는 방식입니다.
각 노드는 포인터에 다음 노드의 정보를 담고 있습니다. 다른 노드의 정보는 담겨져 있지 않습니다.
예를 들어 두 번째 노드는 자기자신과 세 번째 노드의 정보를 가지고 있고, 세 번째 노드는 자기자신과 네 번째 노드의 정보를 가지고 있습니다.
따라서 특정한 데이터(예를 들어 index값이 7인)를 찾을 때 Head노드(index 0)를 찾아서 순서대로 찾아 들어가야 합니다.
1.1 데이터 삽입
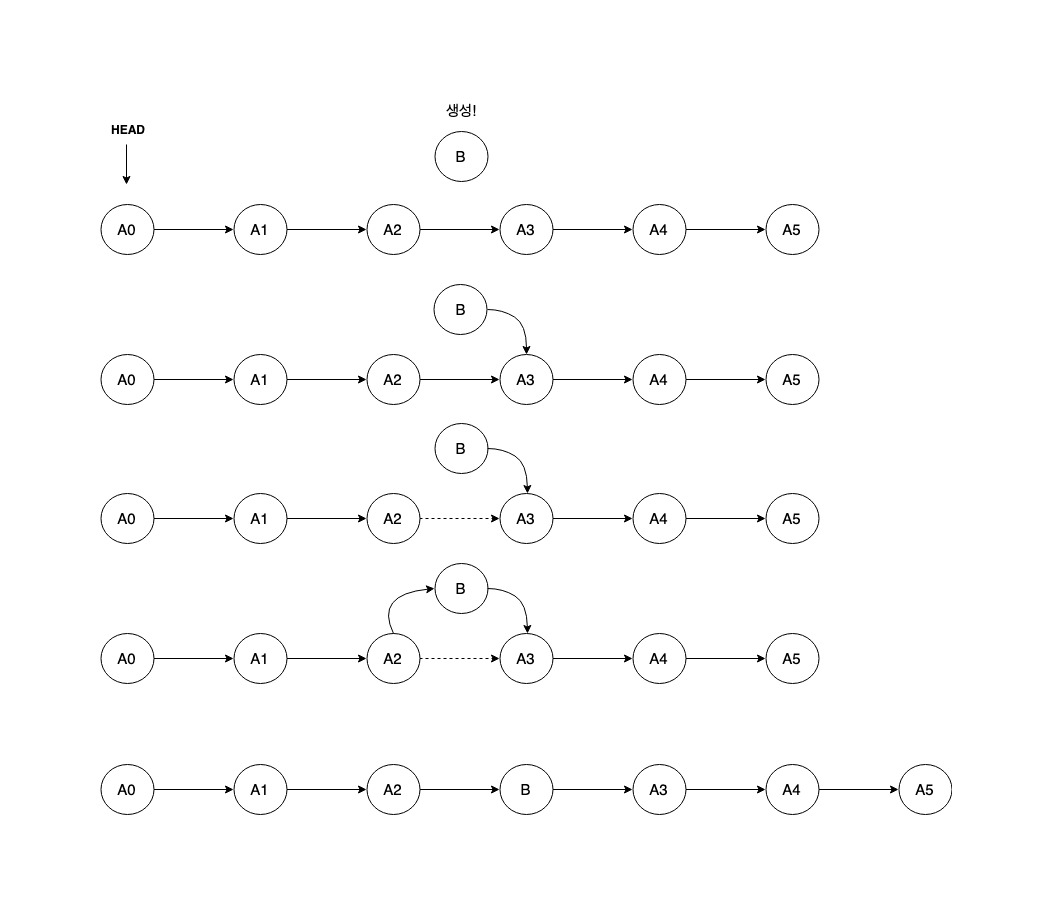 LinkedList의 데이터 삽입 프로세스를 위 그림을 참조하여 정리하면 다음과 같습니다.
LinkedList의 데이터 삽입 프로세스를 위 그림을 참조하여 정리하면 다음과 같습니다.
- 1.새로 생성된 B라는 데이터를 LinkedList의 2번째와 3번째 사이에 삽입하려고 합니다.
- 2.LinkedList는 내 다음 노드의 정보밖에 모르기 때문에 Head노드에서부터 삽입하려는 위치의 이전노드(A2)를 찾아가야 합니다.
- 3.A2의 포인터 정보(A3을 참조하는 정보)를 알아내서 B의 포인터에 할당합니다. 이제 B는 A3노드를 자신의 다음 노드로 인식합니다.
- 4.A2의 포인터를 B를 바라보도록 할당합니다. 이제 A2는 B를 자신의 다음 노드로 인식합니다.
1.2 데이터 삭제
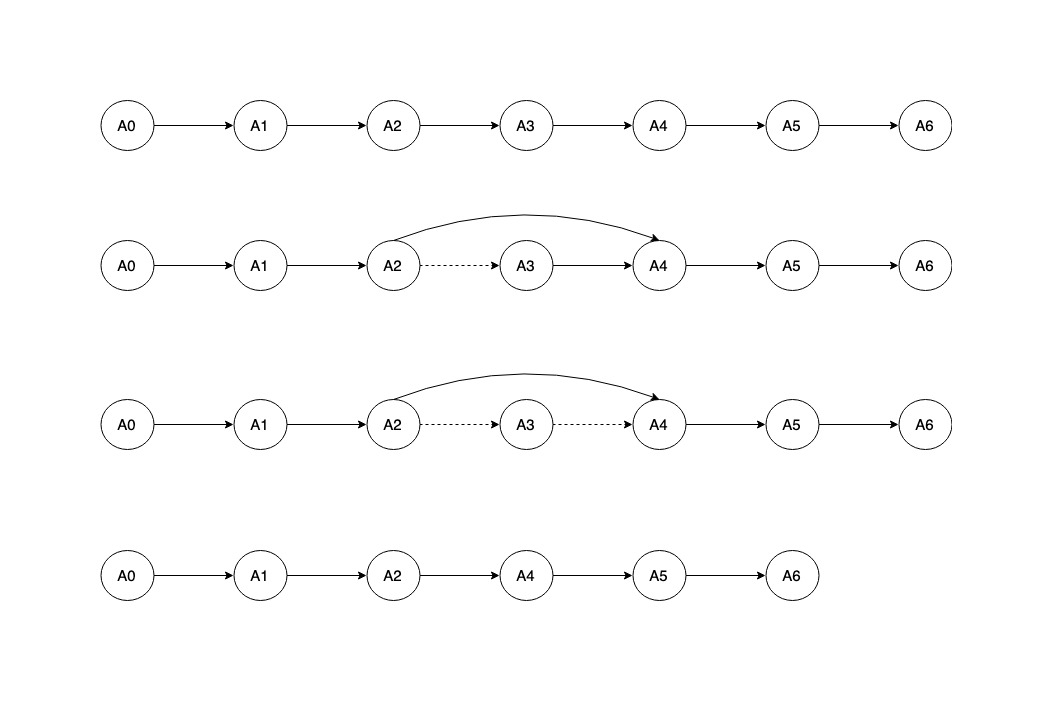 LinkedList의 데이터 삭제 프로세스를 위 그림을 참조하여 정리하면 다음과 같습니다.
LinkedList의 데이터 삭제 프로세스를 위 그림을 참조하여 정리하면 다음과 같습니다.
- 1.A3이라는 데이터를 LinkedList에서 삭제하려고 합니다.
- 2.LinkedList는 내 다음 노드의 정보밖에 모르기 때문에 Head노드에서부터 삭제하려는 위치의 이전노드(A2)를 찾아가야 합니다.
- 3.A2의 포인터를 A3이 바라보는 포인터 값(A4)으로 할당합니다. 이제 A2는 A4노드를 자신의 다음 노드로 인식합니다.
- 4.A3의 포인터 값을 삭제합니다. 이제 A3은 LinkedList의 노드로 인식되지 않습니다.
1.3 장점
- 자료의 삽입과 삭제가 용이
- 리스트 내에서 자료의 이동이 필요하지 않음
- 사용 후 기억 장소의 재사용이 가능
1.4 단점
- 포인터의 사용으로 인해 메모리 저장 공간의 낭비가 있음
- 알고리즘이 복잡함
- 특정 자료의 탐색시간이 많이 소요됨
2. Stack
Stack은 데이터의 삽입과 삭제가 LIFO(Last In First Out)를 따릅니다.
우리가 잘 아는 과자인 프링글스를 생각해 봅시다.
프링글스를 먹기 위해서는 가장 위의(가장 마지막에 쌓인) 과자를 먼저 먹어야 합니다.
Stack도 이런식으로 가장 마지막에 들어왔던 데이터가 먼저 빠져나가게 됩니다.
Stack에서는 데이터의 삽입을 push라고 하고, 데이터의 삭제는 pop이라고 합니다.
Stack은 보통 DFS(Depth First Search, 깊이우선탐색)에 사용됩니다.
2.1 데이터 삽입
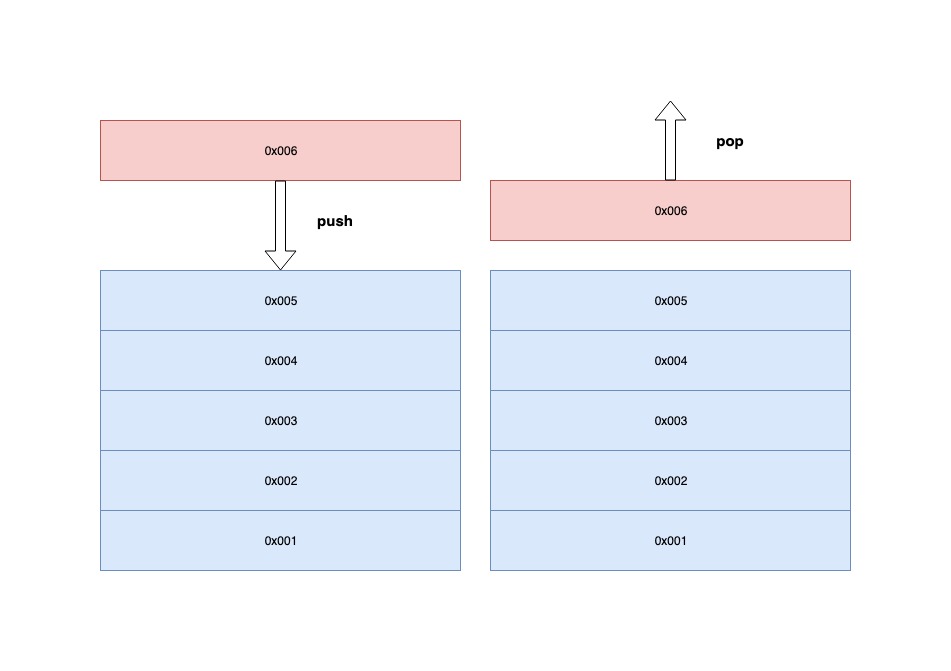
- 1.맨 마지막으로 들어온 데이터의 주소가 0x005인 stack에 0x006주소를 가진 데이터를 삽입(push)하려고 합니다.
- 2.현재 마지막 스택으로 0x005주소를 바라보고 있기 때문에 0x006으로 할당합니다. 그러면 마지막 스택으로 0x006을 바라보게 됩니다.
2.2 데이터 삭제
- 1.맨 마지막으로 들어온 데이터의 주소가 0x006인 stack의 데이터 하나를 삭제(pop)하려고 합니다.
- 2.stack은 LIFO를 따르기 때문에 마지막에 들어온 데이터의 주소인 0x006가 삭제됩니다. 따라서 그 이전에 들어온 데이터의 주소인 0x005를 마지막 스택으로 할당합니다.
- 3.그러면 0x006주소를 가진 데이터는 빠져나가고 맨 마지막 stack의 데이터의 주소는 0x005가 됩니다.
3. Queue
Queue는 데이터의 삽입과 삭제가 Stack과는 반대로 FIFO(First In First Out)를 따릅니다.
병원에 진료를 받으러 갔다고 생각해 봅시다.
접수를 하면 대기줄의 맨 마지막에 등록이 됩니다.
그리고 진료를 하는 의사는 처음에 접수했던 환자 순으로 진료를 하게 됩니다.
Queue도 이런식으로 처음에 들어왔던 데이터가 먼저 빠져나가게 됩니다.
Queue에서는 데이터의 삽입을 enqueue라고 하고, 데이터의 삭제를 dequeue라고 합니다.
Queue는 보통 컴퓨터의 버퍼, BFS(Breadth First Search, 너비우선탐색)에 사용됩니다.
3.1 데이터 삽입
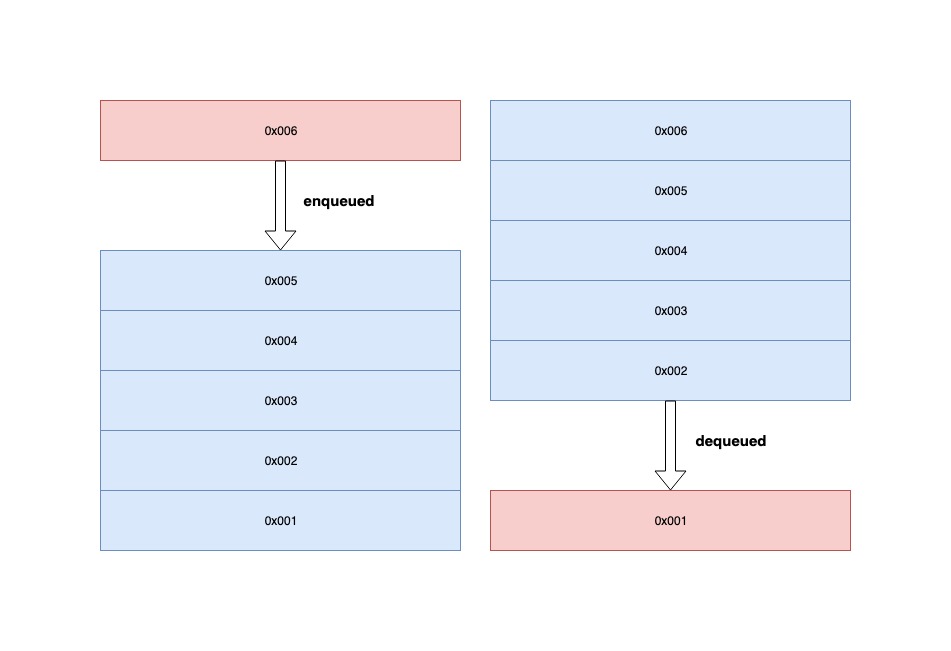
- 1.맨 마지막으로 들어온 데이터의 주소가 0x005인 queue에 주소가 0x006인 데이터를 삽입(enqueue)하려고 합니다.
- 2.현재 마지막 스택으로 0x005주소를 바라보고 있기 때문에 0x006으로 할당합니다. 그러면 마지막 스택으로 0x006을 바라보게 됩니다.
3.2 데이터 삭제
- 1.맨 처음으로 들어온 데이터의 주소가 0x001인 queue의 데이터 하나를 삭제(dequeue)하려고 합니다.
- 2.stack은 FIFO를 따르기 때문에 처음에 들어온 데이터의 주소인 0x001가 삭제됩니다. 따라서 그 이후에 들어온 데이터의 주소인 0x002를 첫 번째 queue로 할당합니다.
- 3.그러면 0x001주소를 가진 데이터는 빠져나가고 첫 번째 queue의 데이터의 주소는 0x002가 됩니다.

